归并排序定义
时间复杂度 O(NlogN)
归并排序的整体思想就是把数据 一分为二,然后将两部分数据分别排序后,再合并到一起的过程。可以用递归完成这个过程,看图理解:
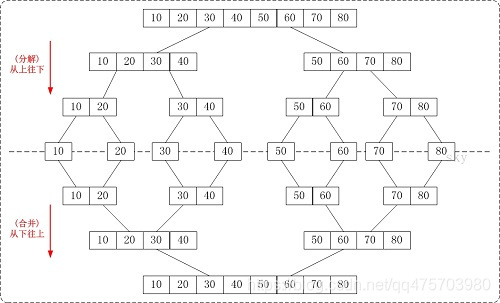
每次将数据分成a/b两组,两组数据分别排序。对a排序时,依然使用归并排序,于是继续将a分成两组,直到每组数据都只有一个时,一个数据本身就是有序的,不需要再排序,然后将讲个数据合并到一起,小的数排前面,大的排后面。不断合并,最后数据就变成有序的了。
这个过程使用了额外的空间,空间复杂度也为O(NlogN)。但是现在,速度往往比空间重要。
代码实现
/**
* 归并排序
* 开始实现代码前先定义好边界问题,这里我们采用前闭后闭的结构,对数组的[left, right] 这个范围排序
* 由于递归排序每次分成两半,这是一个天然递归的结构,所以可以采用递归的方式进行排序,逻辑上会比较简单
* @param arr 数据集合
* @param left 要排序数据的左边界
* @param right 右边界
*/
public static void mergeSort(int[] arr, int left, int right) {
if(left >= right) {
//左边界已经大于右边界,说明此事已经遍历完成,应该停止递归
//要注意,采用递归,就一定需要定义好停止递归的条件,不能无限递归
return ;
}
int mid = (right + left) / 2;//得到中间的位置
mergeSort(arr, left, mid); //先对左半部分递归排序
mergeSort(arr, mid+1, right);//再对右半部分进行递归排序
merge(arr, left, mid, right);//然后重新合并为一个有序数据集
}
private static void merge(int[] arr, int left, int mid, int right) {
//从示例图中我们看到,归并的过程中,需要开辟新的空间来放数组,因此先定义一个我们需要的数组
int[] temp = new int[right - left + 1];
for(int i=left; i<=right; i++) {
temp[i-left] = arr[i]; //把arr [left , right] 这个范围的值赋值给temp
}
int i = left;
int j = mid + 1;
for(int k=left; k<=right; k++) {
if(i > mid) {
//当左边部分的指针已经大于中间位置时,说明左边部分已经全部遍历完了
//此时只需要顺序遍历右边部分即可
arr[k] = temp[j-left];
j++;
} else if(j > right) {
//当右边部分的指针已经大于最大位置时,说明右边部分已经全部遍历完了
//此时只需要顺序遍历左边部分即可
arr[k] = temp[i - left];
i++;
} else if(temp[i-left] < temp[j-left]) {
//比较左右部分哪一个的值比较小,先写入到原数组中,然后对应的左右部分指针后移一位
arr[k] = temp[i-left];
i++;
} else {
arr[k] = temp[j-left];
j++;
}
}
}
归并排序的优化一
如果要排序的数据本身是接近有序的,或者换句话说,如果在归并过程中,数据已经有序,则不用再进行额外的归并操作了,优化如下:
public static void mergeSort(int[] arr, int left, int right) {
if(left >= right) {
return ;
}
int mid = (right + left) / 2;
mergeSort(arr, left, mid);
mergeSort(arr, mid+1, right);
if(arr[mid+1] < arr[mid]) {
//只有左右两边数据还是无序时,才需要merge
merge(arr, left, mid, right);
}
}
通过增加一个判断,就可能少调用mergeSortMerge方法,从而少了很多步操作。当然,因为增加了一个判断,也可能存在降低性能的可能,但是影响不大,特别是对于接近有序的数据,优化效果会特别明显。
归并排序的优化二
前面的代码,我们是在递归到最后一个数时,才返回的:
if(left >= right) {
return ;
}
这里可以在数据比较小时,就不使用递归排序了,通常数据较小时,插入排序会比较快,所以这里可以用插入排序来进行优化:
public static void mergeSort(int[] arr, int left, int right) {
if(right - left <=15) {
insertionSort(arr, l, r);//此时用插入排序
return ;
}
int mid = (right + left) / 2;
mergeSort(arr, left, mid);
mergeSort(arr, mid+1, right);
if(arr[mid+1] < arr[mid]) {
//只有左右两边数据还是无序时,才需要merge
merge(arr, left, mid, right);
}
}
// 对arr[l...r]范围的数组进行插入排序
private void insertionSort(int[] arr, int l, int r){
for( int i = l+1 ; i <= r ; i ++ ) {
int[] e = arr[i];
int j;
for (j = i; j > l && arr[j-1] > e; j--)
arr[j] = arr[j-1];
arr[j] = e;
}
return;
}
自底向上排序
上述例子,我们是自顶向下进行排序的,对于归并排序,我们也可以使用自底向上的排序
public static void mergeSortBU(int[] arr, int n){
for( int sz = 1; sz <= n ; sz += sz ) {
//注意定义好边界问题,不能超过边界n, 所以i +sz < n, Math.min(i+sz+sz-1,n-1)
for( int i = 0 ; i +sz < n ; i += sz+sz ) {
// 对 arr[i...i+sz-1] 和 arr[i+sz...i+2*sz-1] 进行归并
merge(arr, i, i+sz-1, Math.min(i+sz+sz-1,n-1) );
}
}
}
从统计意义上将,自底向上排序性能比使用递归的自顶向下稍微差一点点。
另外,从代码中可以看到,自底向上没有使用数组的索引去获取元素,这很重要,因为这意味着链表也可以使用归并排序,只需要修改具体的归并过程即可(即修改merge方法);
自底向上的优化思想和前面两个类似,这里没有写代码了。
附上自动生成测试数组的代码
public static int[] randomArray(int length) {
int[] arr = new int[length];
Random random = new Random();
for(int i=0; i<length; i++) {
arr[i] = random.nextInt(100);
}
//自动生成随机数组,先进行一次原始数据打印
System.out.println(Arrays.toString(arr));
return arr;
}