归并排序(Merge Sort)是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列。
归并排序的具体做法:
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序最常用的是二路归并,即把两个小的有序的序列和并成一个大的有序序列:合二为一。
一个二路归并的流程图是这样的:
多路归并无非是多个有序的小序列合并成一个大的有序序列,道理和二路归并一样。
先来看下如何把两个有序的序列合并成一个大的有序序列,代码如下:
/*
*把有序序列a和b,合并成c
*该算法成立前提: a和b已经有序
*/
void merge(int a[], int na, int b[], int nb, int c[])
{
if(a && b && c && na >0 && nb >0)
{
int i,j,k;
i = j = k = 0;
//不断地比较a和b的头部元素,较小的存入c
while(i < na && j < nb)
{
if(a[i] <= b[j]) // <= 保持算法的稳定性
c[k++] = a[i++];
else
c[k++] = b[j++];
/*另一种更有效的做法是这样的
while(i < na && a[i] <= b[j])
c[k++] = a[i++];
while(j < nb && b[j] < a[i])
c[k++] = b[j++];
*/
}
//把a或b中剩余的元素直接存入c
/* 也可以这样:
* memcpy(c+k, a+i, (na-i)sizeof(int));
* 下同
*/
while(i < na)
c[k++] = a[i++];
while(j < nb)
c[k++] = b[j++];
}
}可以看出,二路归并的时间复杂度是O(n),n是原序列的数据规模。以上代码是归并排序的基础,弄懂了它,就很好写归并排序了,看下归并排序的流程图:
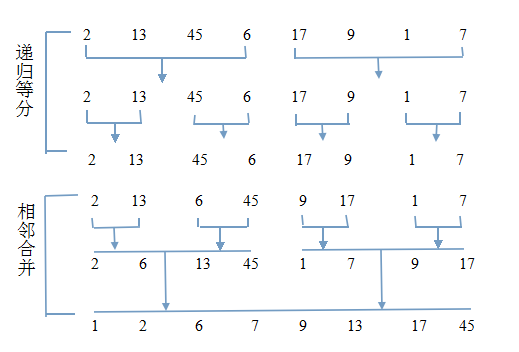
可以看出,上半部分不断地递归深入:不断地均分原序列,直到每一部分只含有一个元素。下半部分,开始递归返回,通过反复调用二路归并算法,把相邻的有序子序列合并成一个规模更大的序列。
理解了这些,相信就很容易写出归并排序的代码了:
//把[first, mid]和[mid+1, last]范围内的数据合并
void mergeArray(int a[], int b[], int first, int mid, int last)
{
int i, j, k;
i = first, j = mid + 1, k = 0;
while (i <= mid && j <= last)
{
while(i <= mid && a[i] <= a[j])
b[k++] = a[i++];
while(j <= last && a[j] < a[i])
b[k++] = a[j++];
}
/* 也可以这样:
* memcpy(b+k, a+i, (mid-i+1)sizeof(int));
* 下同
*/
while (i <= mid)
b[k++] = a[i++];
while (j <= last)
b[k++] = a[j++];
//[first,last]范围内的数据已有序,则写回原数组
for (i = 0; i < k; i++)
a[first + i] = b[i];
}
void mergesort(int a[], int b[], int first, int last)
{
if (first < last)
{
int mid = first + ((last - first) >> 1);
mergesort(a, b, first, mid);
mergesort(a, b, mid + 1, last);
mergeArray(a, b, first, mid, last);
}
}
void MergeSort(int a[], int n)
{
if (a && n > 1)
{
int *b = new int[n]; //构建辅助数组
mergesort(a, b, 0, n - 1);
delete[]b;
}
}在排序过程中,我们使用了一个相同大小的临时辅助数组。
算法分析:
1.算法的复杂度
对数组长度为n的序列进行归并排序,则大约要进行logn次归并,每一次合并都是线性时间O(n)。故粗略的计算出归并排序的时间复杂度是O(nlogn)(最好、最差都是这样)。空间复杂度是O(n)。详细的时间复杂度分析是这样的:
对长度为n的序列归并排序,需要递归的对长度为n/2的子序列进行归并排序,最后把两段子序列二路归并。递推关系是这样的:T(n)=2T(n/2)+O(n),显然T(1)=O(1),解得T(n)=o(nlogn)。
2.稳定性
归并排序是稳定的,并且是时间复杂度为o(nlogn)的几种排序(快速排序、堆排序)中唯一稳定的排序算法。
3.存储结构
顺序存储和链式存储都行。
另外,归并排序多用于外排序中。
转载请注明出处,本文地址:http://blog.csdn.net/zhangxiangdavaid/article/details/34463409
若是有所帮助,顶一个哦!
所有内容的目录
- CCPP Blog 目录