目录
冒泡排序(Bubble Sort)
选择排序(Select Sort)
插入排序(InsertSort)
希尔排序(ShellSort)
计数排序(CountSort)
快速排序(QuickSort)
归并排序(Merge Sort)
堆排序(Heap Sort)
桶排序(Bucket Sort)
基数排序(Radix Sort)
总结
冒泡排序(Bubble Sort)
例如:2,32,4,45,6,334,1,33
相邻的两个数之间若前一个数>后一个数,他俩就交换。
第一次交换结果:2 4 32 6 45 1 33 334
第一次交换,最大的一个数就确定了,下次遍历次数就-1。
第二次交换结果:2 4 6 32 1 33 45 334
第二次交换,第二大的数也确定了,下次遍历次数就-2。
以此类推,得出结果:1 2 4 6 32 33 45 334
#include<iostream>
using namespace std;
void Bubblesort(int a[], int len)
{
if (a == NULL || len <= 0)return;
for (int j = 0; j < len-1; j++) {
for (int i = 0; i + 1 < len-j; i++)
{
if (a[i] > a[i + 1])
swap(a[i], a[i + 1]);
}
for (int i = 0; i < len; i++)
cout << a[i] << " ";
cout<<endl;
}
}
int main()
{
int arr[] = { 2,32,4,45,6,334,1,33 };
Bubblesort(arr, sizeof(arr) / sizeof(arr[0]));
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
cout << arr[i] << " ";
return 0;
}优化:
我们定义一个标记flag,表示最后一次交换的位置,更新i,内层循环需要交换的位置就是0~len-flag-2,外层循环遍历次数也变为flag-1次。
#include<iostream>
using namespace std;
void BubbleSort(int len, int a[])
{
int flag;
for (int i = 0; i < len - 1; i++)
{
//最后一次交换的位置
flag = 0;
for (int j = 0; j < len - i - 1; j++)
{
if (a[j] > a[j + 1])
{
swap(a[j], a[j + 1]);
flag = j + 1;
}
}
//没有发生交换
if (flag == 0)break;
//内层循环更新到上一次最后交换的位置
i = len - flag - 1;
}
}
int main()
{
int a[] = { 5,4,3,2,1 };
BubbleSort(sizeof(a) / sizeof(a[0]), a);
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
cout << a[i] << " ";
cout << endl;
return 0;
}选择排序(Select Sort)
每次遍历找到最值(最大值或最小值)放入相应位置。
例如:2,32,4,45,6,334,1,33
找到最小值下标6,和第一个个值交换。
第一次遍历:1 32 4 45 6 334 2 33
第二次遍历从下标1开始找到最小的为下标6和第二个值交换。
第二次遍历:1 2 4 45 6 334 32 33
一此类推,得出结果:1 2 4 6 32 33 45 334
#include<iostream>
using namespace std;
void SelectSort(int len, int a[])
{
if (a == NULL || len <= 0)return;
int i;
int j;
int nMin;
for (i = 0; i < len-1; i++)
{
nMin = i;
for (j = i+1; j < len; j++)
{
if (a[j] < a[nMin])
nMin = j;
}
if (nMin != i)swap(a[i],a[nMin]);
}
}
int main()
{
int a[] = { 2,32,4,45,6,334,1,33 };
SelectSort(sizeof(a) / sizeof(a[0]), a);
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
cout << a[i] << " ";
return 0;
}插入排序(InsertSort)
适用范围:(1)元素少。(2)每个元素在排序前的位置距其最终排好序的位置不远的时候。
将待排序数据分成两部分,一部分有序,一部分无序,将无序元素依次插入到有序中去,完成排序。
例如: 2,32,4,45,6,334,1,33
首先有序部分是2,无序部分是32,4,45,6,334,1,33
用i,j分别记录有序部分位置和无序部分位置。
需要插入n-1次,保存当前需要插入的无序元素。
然后倒序遍历有序元素,如果无序元素比有序元素大那就插入在这个有序元素的下一个位置,如果比它小,那就将有序元素向后移一位继续遍历。循环往复。
2,32,4,45,6,334,1,33
2,4,32,45,6,334,1,33
2,4,32,45,6,334,1,33
2,4,6,32,45,334,1,33
2,4,6,32,45,334,1,33
1,2,4,6,32,45,334,33
1,2,4,6,32,33,45,334
#include<iostream>
using namespace std;
void InsertSort(int len, int a[])
{
if (a == NULL || len <= 0)return;
int i;
int j;
int temp;
for (i = 1; i < len; i++)
{
j = i - 1;
temp = a[i];
while (j >= 0 && a[j] > temp)
{
a[j+1] = a[j];
j--;
}
a[j + 1] = temp;
}
}
int main()
{
int a[] = { 2,32,4,45,6,334,1,33 };
InsertSort(sizeof(a) / sizeof(a[0]), a);
for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++)
cout << a[i] << " ";
return 0;
}希尔排序(ShellSort)
将待排序数据分组,各组之内进行插入排序。(间隔分组 缩小增量)
(1)确定间隔
(2)分组(间隔是几就是分几组)
(3)各组插入排序
例:

按间隔分组后,23,45,43插入排序,1,2插入排序,73,6插入排序,11,8插入排序。
排完序后如下图,继续分组。

按间隔分组后,23,6,43,73,45插入排序,1,8,2,11插入排序。
最后每个元素在排序前的位置距其最终排好序的位置不远的时候也就是插入排序适用的条件。
排完后如下图,继续分组。

最后排完序

计数排序(CountSort)
元素分配密集,且重复出现频率较高,找到最值,统计计数器个数,对每个元素出现次数进行统计。
(1)找到最大值,最小值
(2)创建数组0~max-min
(3)计数
(4)排序:计数值非0,索引+最小值。
#include<iostream>
using namespace std;
void CountSort(int len, int a[])
{
if (len <= 0 || a == NULL)return;
int maxx=a[0];
int minn=a[0];
for (int i = 1; i < len; i++)
{
maxx = max(maxx, a[i]);
minn = min(minn, a[i]);
}
int* Count = (int*)malloc(sizeof(int) * (maxx - minn + 1));
memset(Count, 0, sizeof(int) * (maxx - minn + 1));
for (int i = 0; i < len; i++)
{
Count[a[i] - minn]++;
}
int j = 0;
for (int i = 0; i < maxx - minn + 1; i++)
{
while (Count[i] != 0)
{
a[j] = minn + i;
Count[i]--;
j++;
}
}
free(Count);
Count = NULL;
for (int i = 0; i < len; i++)
cout << a[i] << " ";
}
int main()
{
int a[] = { 2,32,4,45,6,334,1,33 };
CountSort(sizeof(a) / sizeof(a[0]), a);
return 0;
}
优化:
从计数数组的第二个元素开始,后面每一个都加上前面所有元素之和,数组大小代表了该数据在序列中的位置,所以从后往前输出。
#include<iostream>
using namespace std;
void CountSort(int len, int a[])
{
if (len <= 0 || a == NULL)return;
int maxx=a[0];
int minn=a[0];
for (int i = 1; i < len; i++)
{
maxx = max(maxx, a[i]);
minn = min(minn, a[i]);
}
int* Count = (int*)malloc(sizeof(int) * (maxx - minn + 1));
memset(Count, 0, sizeof(int) * (maxx - minn + 1));
for (int i = 0; i < len; i++)
{
Count[a[i] - minn]++;
}
for (int i = 1; i < maxx - minn + 1; i++)
{
Count[i] += Count[i - 1];
}
int* arr = (int*)malloc(len * sizeof(int));
for (int i = len - 1; i >=0; i--)
{
arr[Count[a[i] - minn] - 1] = a[i];
Count[a[i] - minn]--;
}
for (int i = 0; i < len; i++)
cout << arr[i] << " ";
free(Count);
Count = NULL;
free(arr);
arr = NULL;
}
int main()
{
int a[] = { 2,2,2,77,77,3,3,4,66,6,4,3,2,1 };
CountSort(sizeof(a) / sizeof(a[0]), a);
return 0;
}快速排序(QuickSort)
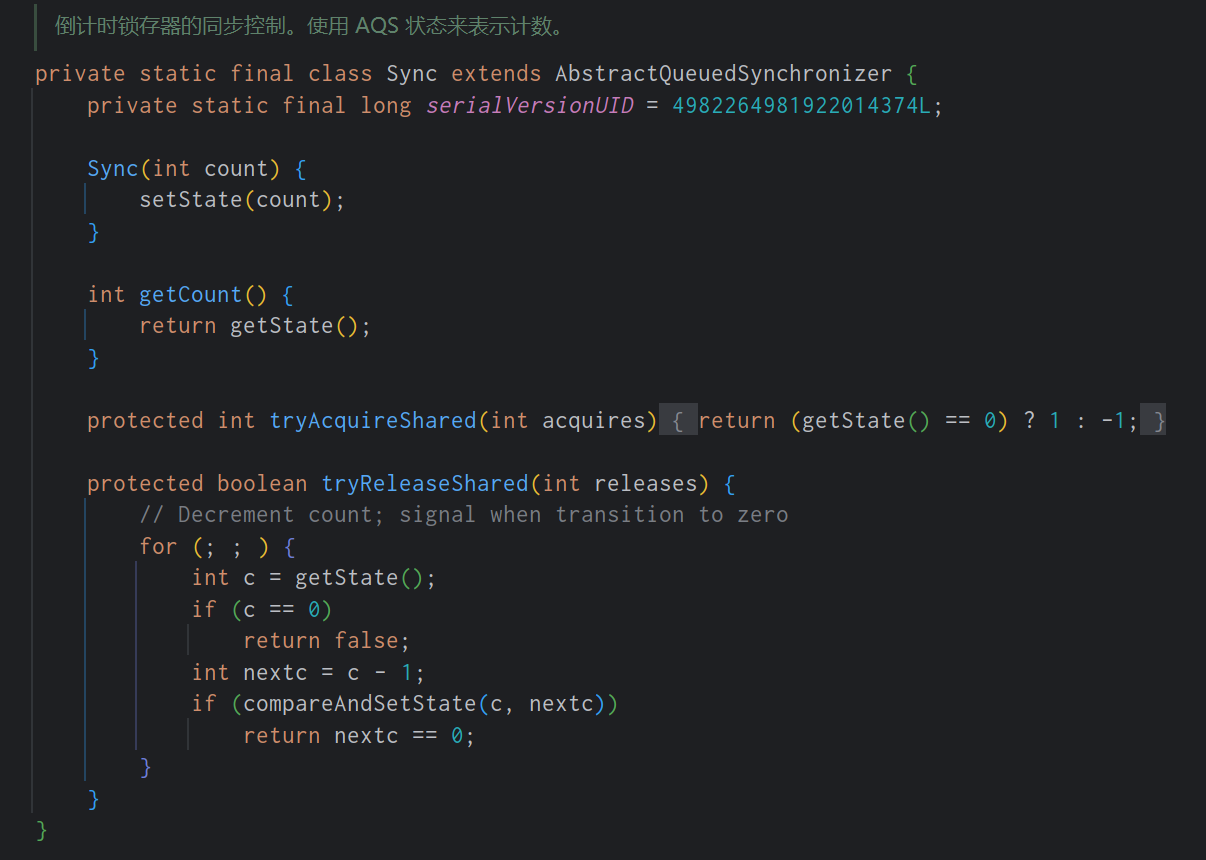
首先选出标准值,然后(挖坑填补法)从右到左找小于标准值的,放入左侧坑,然后从左到右找大于标准值的放入右侧坑循环,然后两个指向位置相遇了就放入标准值,然后继续找,左:(起始位置,标准值-1),右(标准值+1,结束位置)。
例如:
将左侧9作为标准值,从右向左找小于9的,找到6。

然后将6放入左坑,现在从左往右找比9大的放右坑。
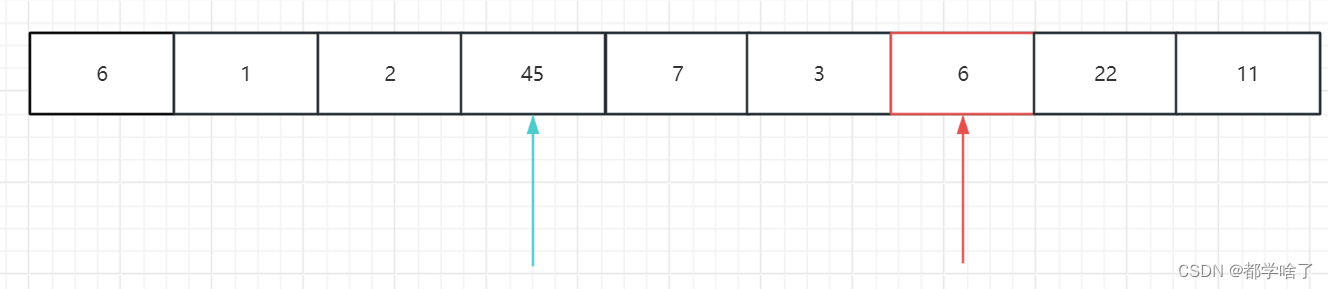
找到45放到右坑,然后再从右向左找小于9的放左坑,找到3。
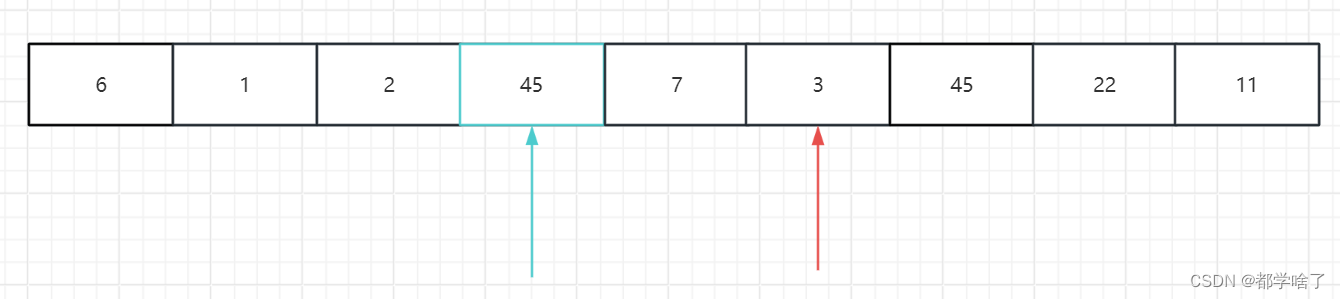
然后再从左往右找比9大的,发现没有了,标记相遇了。

放入标准值9。

然后在(起始位置,标记值-1) , (标记值+1,结束位置)重复以上过程直到蓝色>=红色标记结束。
#include <stdio.h>
#include <iostream>
#include <math.h>
#include <algorithm>
using namespace std;
int part(int* a, int left, int right)
{
int i = left, j = right,k = a[left];
while (i < j)
{
while (i<j )
{
if (a[j] < k)
{
a[i] = a[j];
i++;
break;
}
j--;
}
while (i < j)
{
if (a[i] >k)
{
a[j] = a[i];
j--;
break;
}
i++;
}
}
a[i] = k;
return i;
}
void Quicksort(int* a, int left, int right)
{
if (a == NULL || left >= right)return;
int mid;
mid = part(a, left, right);
Quicksort(a, left, mid - 1);
Quicksort(a, mid + 1, right);
}
int main()
{
int a[] = { 9,1,2,45,7,3,6,22,11 };
int len = sizeof(a) / sizeof(a[0]);
Quicksort(a, 0, len-1);
for (int i = 0; i < len; i++)
{
cout << a[i] << " ";
}
cout << endl;
return 0;
}优化:
选择最右侧的值作为基准元素,在代码中,基准元素前期不需要移动,只需在最后移动就行。
定义nsmall为最后一个小于基准元素的位置。
(1)做标记nsmall。
(2)遍历:从左到右遍历,当前值小于基准值,++nsmall和left是否相等,不相等交换。
(3)标准值放入。
(4)左半部分。
(5)右半部分。
#include <iostream>
using namespace std;
int part(int* a, int left, int right) {
int nsmall = left - 1;
for (left; left < right; left++)
{
if (a[left] < a[right])
{
if (++nsmall != left)
{
swap(a[nsmall], a[left]);
}
}
}
if (++nsmall != right)
swap(a[nsmall], a[right]);
return nsmall;
}
void Quicksort(int* a, int left, int right) {
if (a == NULL || left >= right)return;
int mid = part(a, left, right);
Quicksort(a, left, mid - 1);
Quicksort(a, mid + 1, right);
}
int main() {
int a[] = { 1, 43, 4, 6, 21, 23, 77, 8, 5, 3 };
int len = sizeof(a) / sizeof(a[0]);
Quicksort(a, 0, len - 1);
for (int i = 0; i < len; i++) {
cout << a[i] << " ";
}
cout << endl;
return 0;
}
其它优化:
(1)基准值选取:三选一(起始,中间,结束位置选取中数),九选一
(2)基准值聚集(数据重复,基准值选完有重复的把他们聚集)
(3)分割至元素较少(<16)然后插入排序
(4)循环+申请空间(递归要是内存不够会出现异常)
归并排序(Merge Sort)
将多个有序数组进行合并。
例如:
先分成两部分,然后继续往下分。(这里是将两个有序数组合并,多个也一样)
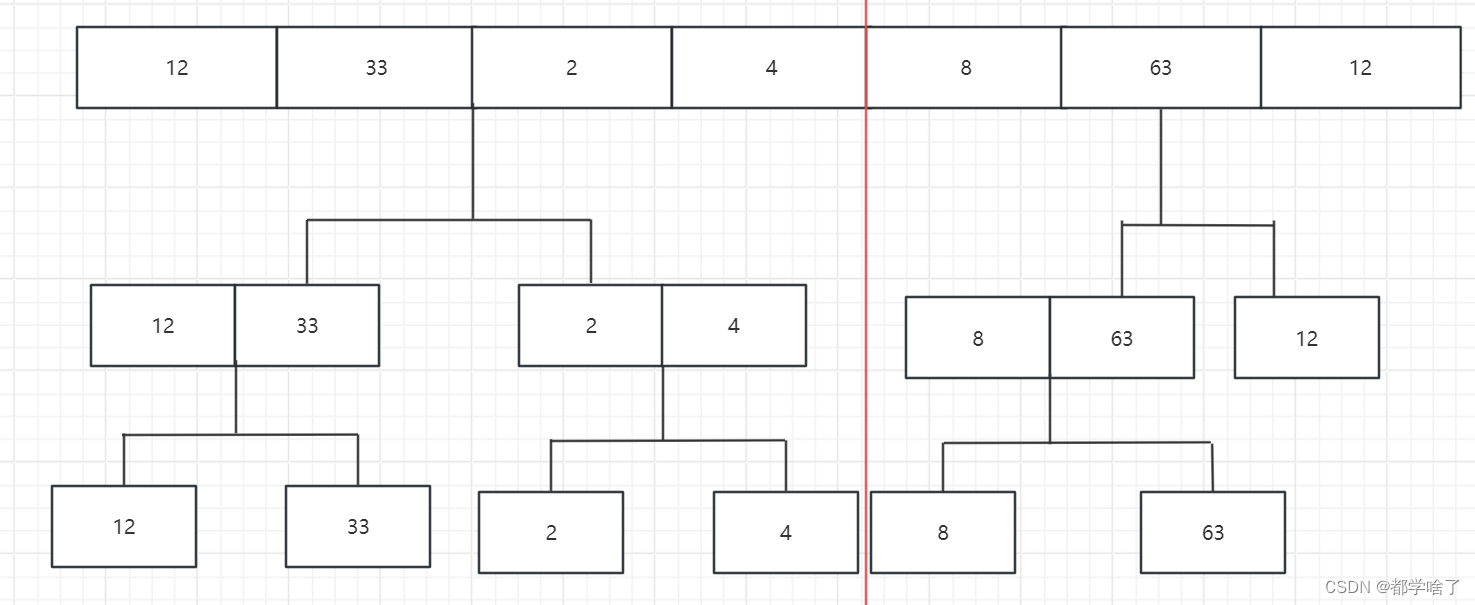
然后从下往上合并,33比12小,所以12,33,2比4小,2,4,然后继续往上合并,2比12小放12前面,4比12小放12前面后面元素都一起拿过来,2,4,12,33,然后其余同理。

步骤:
(1)找中间位置。
(2)分成两部分:左(起始位置,中间位置)右(中间位置+1,结束位置)
(3)合并。
#include<iostream>
using namespace std;
void Merge(int a[], int begin, int end)
{
int begin1 = begin;
int end1 = begin + (end - begin) / 2;
int begin2 = end1 + 1;
int end2 = end;
int* ptemp = (int*)malloc(sizeof(int)*(end-begin+1));
int i=0;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin2] < a[begin1])
{
ptemp[i++] = a[begin2++];
}
else {
ptemp[i++] = a[begin1++];
}
}
while (begin1 <= end1)
{
ptemp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
ptemp[i++] = a[begin2++];
}
for (int j = 0; j < end - begin + 1; j++)
{
a[begin + j] = ptemp[j];
}
free(ptemp);
ptemp = NULL;
}
void MergeSort(int a[], int begin, int end)
{
if (a == NULL || begin >= end)return;
int Mid = begin + (end - begin) / 2;
MergeSort(a, begin, Mid);
MergeSort(a, Mid + 1, end);
Merge(a, begin, end);
}
int main()
{
int a[] = { 12,33,2,4,8,63,12 };
int len = sizeof(a) / sizeof(a[0]);
MergeSort(a, 0, len - 1);
for (int i = 0; i < len; i++)
{
cout << a[i] << " ";
}
return 0;
}堆排序(Heap Sort)
每次找最值,将最值放在相应位置上。
堆:大根堆(大堆),小根堆(小堆)。
(我们这里按大根堆来)首先创建初始堆。
例:
首先我们创建一颗完全二叉树,然后进行调整,父亲节点要比孩子节点大(父亲节点0~n/2-1)

3比1大调整
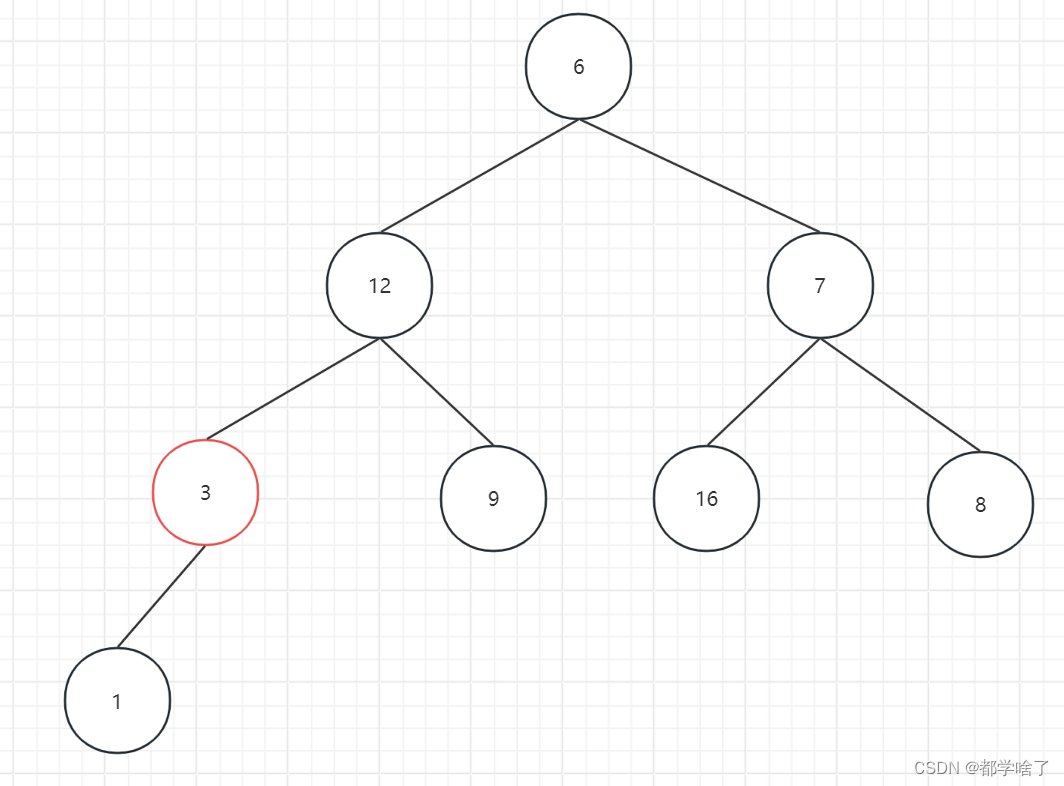
16比7大调整
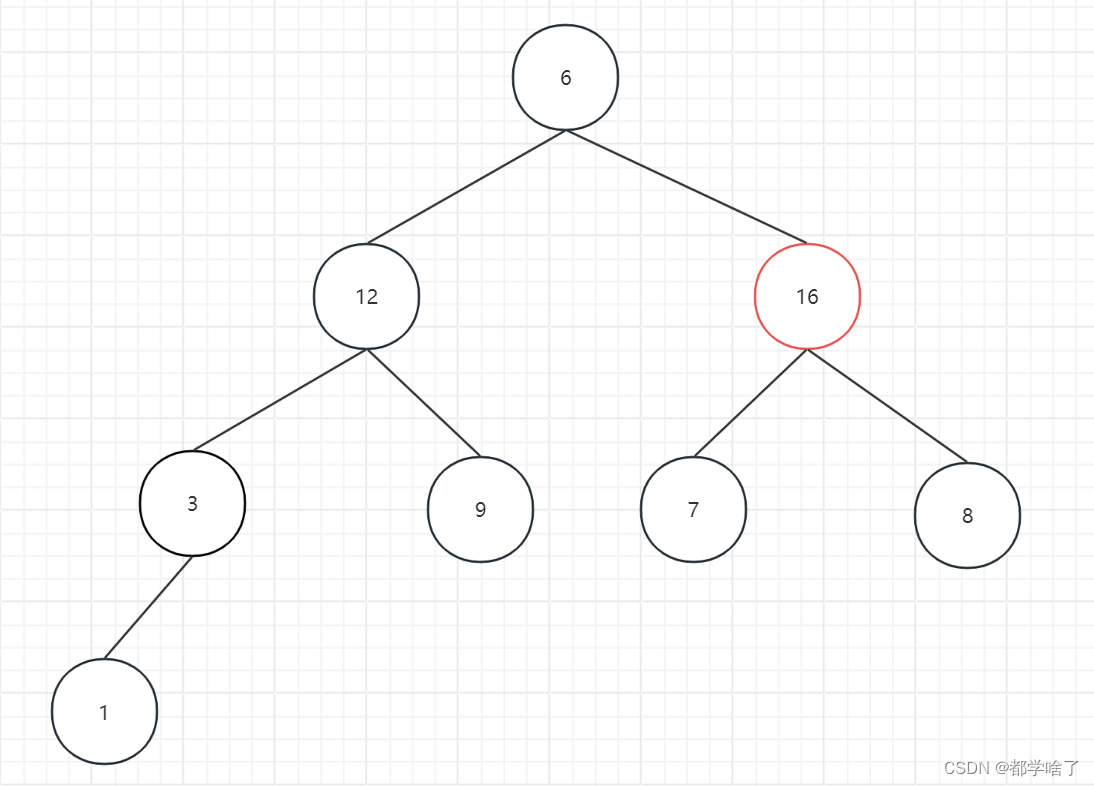
12比9大不用调整

16比6大调整

6比8小调整
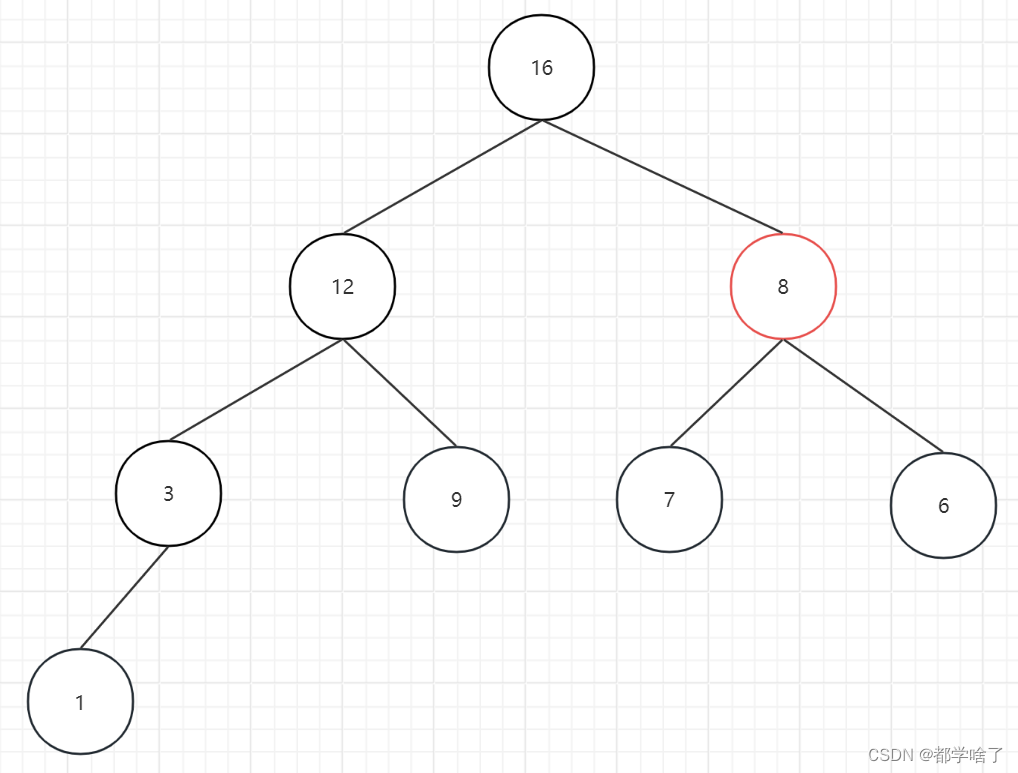
得到初始堆:16,12,8,3,9,7,6,1
然后开始排序,顶末交换,也就是第一个和最后一个交换
1,16交换变为:1,12,8,3,9,7,6,16。
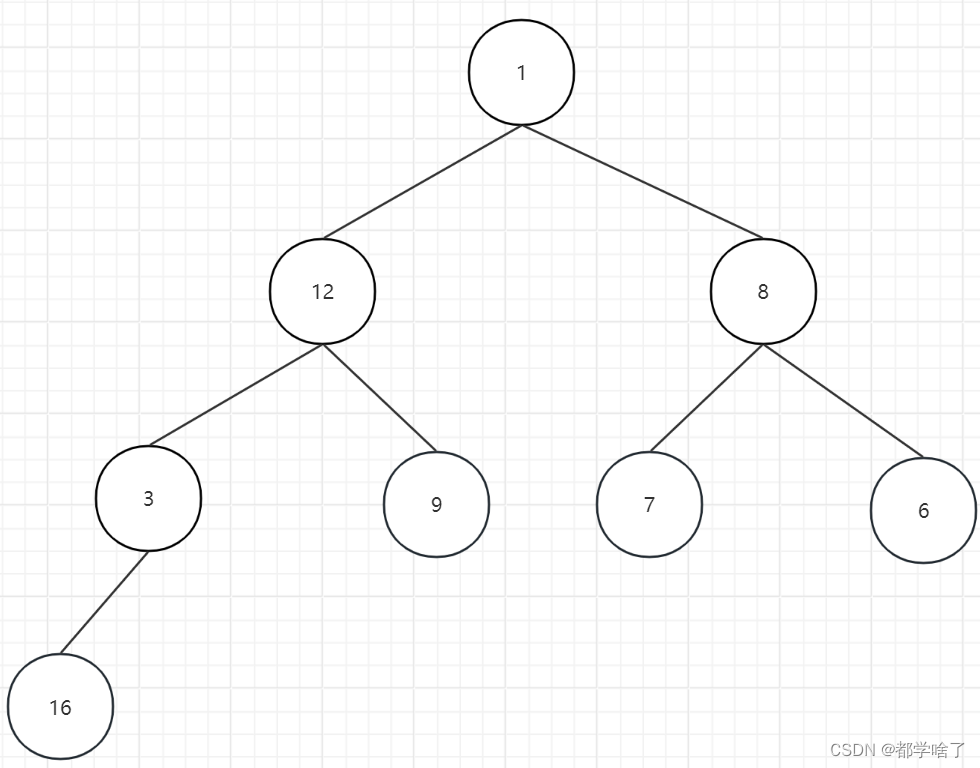
16排好了我们就不看16了,然后我们调整堆顶。

调整完为12,9,8,3,1,7,6,16。
然后继续交换调整,重复上面步骤,直到剩一个。
9,6,8,3,1,7,12,16。
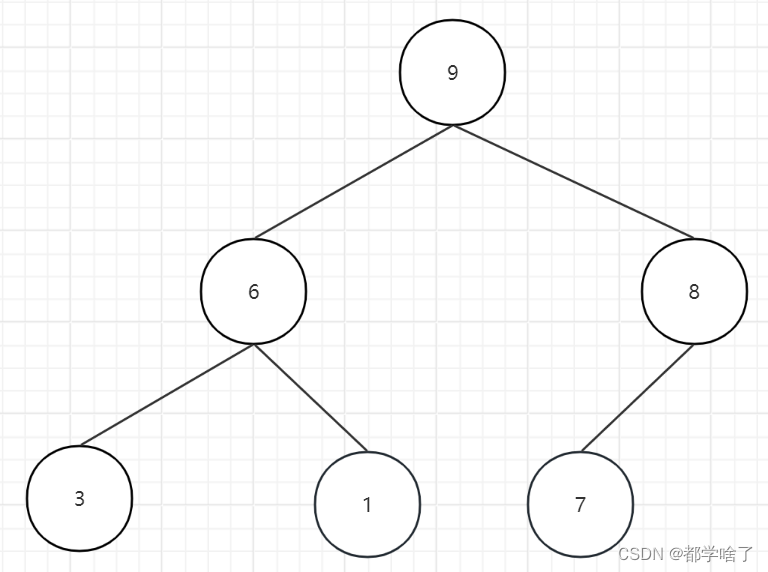
8,6,7,3,1,9,12,16。

7,6,1,3,8,9,12,16。
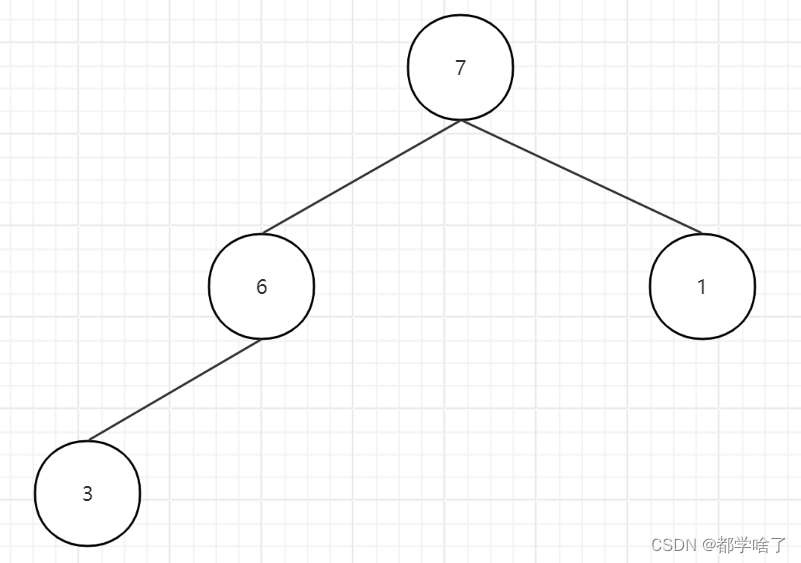
6,3,1,7,8,9,12,16。
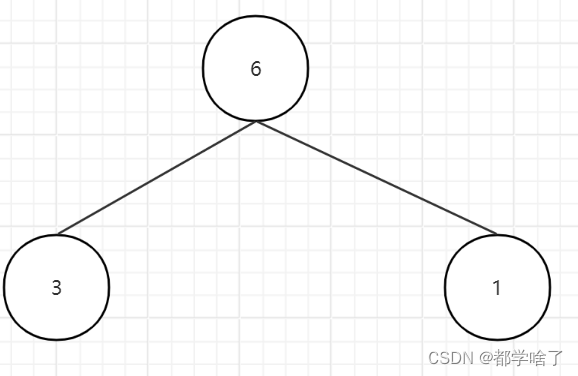
3,1,6,7,8,9,12,16。

结果:1,3,6,7,8,9,12,16。
步骤:
(1)创建初始堆:依次调整各个父亲节点。
(2)顶末交换,调整堆顶,直到只剩下1一个元素。
调整函数:先看孩子个数,然后找孩子里的最大值,最大值比父亲小结束,比父亲大交换。
#include<iostream>
using namespace std;
#define LEFT SwapId*2+1
#define RIGHT SwapId*2+2
void Adjust(int a[], int len, int SwapId)
{
int maxx;
//因为LEFT一定有
for (maxx = LEFT; maxx < len; maxx = LEFT)
{
if (RIGHT < len)
{
if (a[RIGHT] > a[maxx])
{
maxx = RIGHT;
}
}
if (a[maxx] > a[SwapId])
{
swap(a[maxx], a[SwapId]);
SwapId = maxx;
}
else {
break;
}
}
}
void HeapSort(int a[], int len)
{
if (a == NULL || len <= 0)return;
for (int i = len/2 - 1; i >= 0; i--)
{
Adjust(a, len, i);
}
for (int i = len - 1; i > 0; i--)
{
swap(a[0], a[i]);
Adjust(a, i, 0);
}
}
int main()
{
int a[] = { 12,33,2,4,8,63,23,69,1,12 };
int len = sizeof(a) / sizeof(a[0]);
HeapSort(a, len);
for (int i = 0; i < len; i++)
{
cout << a[i] << " ";
}
return 0;
}桶排序(Bucket Sort)
原始:为小数服务的[0,1)相同位数的小数。
延申:整数。
桶与桶之间相互有序。
(1)桶,各桶范围。
(2)各桶内排序(Bubble Sort)。
(3)放回后依次遍历各条链表(哈希)。
(4)释放(先链表,后表头)。
基数排序(Radix Sort)
(LSD从低位优先,MSD高位优先。一般用LSD)
例:
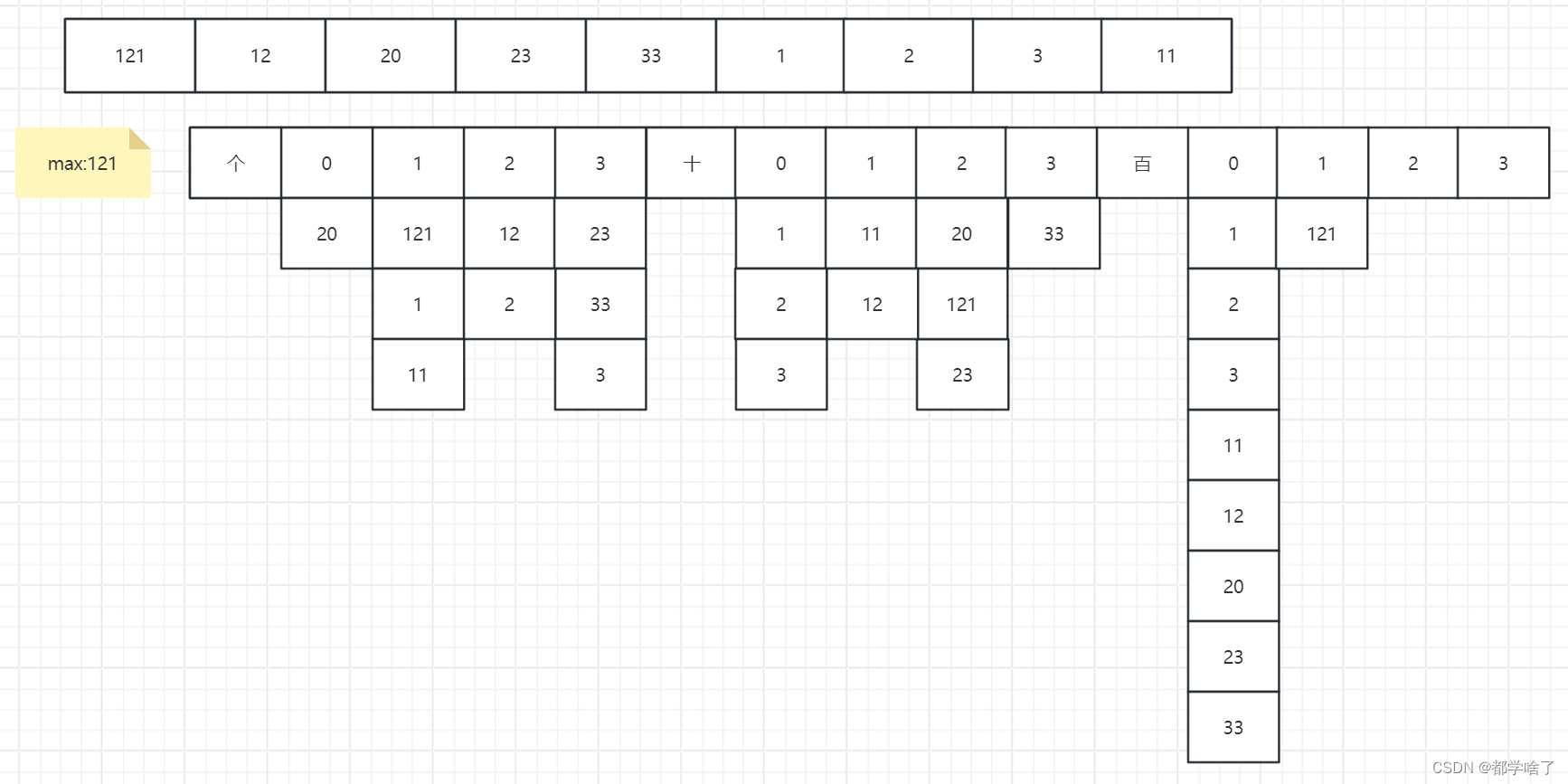
(1)先找最大值。
(2)计算最大值位数。
(3)按位处理:申请组,拆位将数据入组(尾插),表内元素放回原数组,释放。
总结
稳定:排序前后相对位置未发生改变,保证多次排序结果相同,最稳定的就是基数排序,其余的(判断条件>=可能就不稳定了)
| 名称 | 最优时间复杂度 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 |
| 冒泡排序 | 稳定 | ||||
| 选择排序 | ------ | ------ | 不稳定 | ||
| 插入排序 | 稳定 | ||||
| 希尔排序 | ------- | ------ | ------- | 不稳定 | |
| 快速排序 | 不稳定 | ||||
| 归并排序 | 稳定 | ||||
| 堆排序 | 不稳定 | ||||
| 基数排序 | 稳定 |
(注:k是最大值位数)
注: